HELIOS: Harmonizing Early Fusion, Late Fusion, and LLM Reasoning for Multi-Granular Table-Text Retrieval

Figure 1: Overview of HELIOS. The initial graph Ginit is early-fused to generate a data graph Gd. (1) Edges are retrieved using the query to form a candidate bipartite subgraph Gc. (2) Query-relevant nodes are identified and expanded to form Gl. (3) LLM performs aggregation and passage verification for final refinement.
Abstract
Table-text retrieval aims to retrieve relevant tables and text to support open-domain question answering. Existing studies use either early or late fusion, but face limitations. Early fusion pre-aligns a table row with its associated passages, forming "stars," which often include irrelevant contexts and miss query-dependent relationships. Late fusion retrieves individual nodes, dynamically aligning them, but risks missing relevant contexts. Both approaches also struggle with advanced reasoning tasks, such as column-wise aggregation and multi-hop reasoning.
To address these issues, we propose HELIOS, which combines the strengths of both approaches through three key stages: (1) Edge-based bipartite subgraph retrieval identifies finer-grained edges between table segments and passages, effectively avoiding irrelevant contexts. (2) Query-relevant node expansion identifies the most promising nodes, dynamically retrieving relevant edges to grow the bipartite subgraph. (3) Star-based LLM refinement performs logical inference at the star graph level, supporting advanced reasoning tasks.
Experimental results show that HELIOS outperforms state-of-the-art models with significant improvements up to 42.6% and 39.9% in recall and nDCG, respectively, on the OTT-QA benchmark.
Motivation
Open-domain question answering over tables and text is challenging due to the need to bridge structured tables and unstructured passages. Existing methods face three key limitations:

Figure 2: Three cases where existing methods struggle: (a) Inadequate granularity of retrieval units leading to inaccurate results. (b) Entity linking cannot capture query-dependent relationships. (c) Inability to perform advanced reasoning such as table aggregation and multi-hop reasoning.
Inadequate Granularity
Early fusion includes query-irrelevant passages, while late fusion may retrieve incomplete information.
Missing Query-Dependent Links
Pre-defined entity links fail to capture relationships that depend on the specific query context.
Lack of Advanced Reasoning
Semantic similarity alone cannot handle column-wise aggregation or multi-hop reasoning tasks.
Proposed Method
HELIOS operates in three carefully designed stages, each with an optimal granularity for its specific purpose:
Edge-based Bipartite Subgraph Retrieval
This stage constructs and retrieves from a bipartite data graph through:
- Early Fusion: Offline construction of edges between table segments and passages via entity linking
- Edge-level Multi-vector Encoding: Using ColBERTv2 for fine-grained embeddings that capture richer information
- Two-stage Retrieval: Initial retrieval followed by reranking for precise edge selection
This edge-level approach balances between eliminating irrelevant contexts (star graph issue) and avoiding partial information (node-based issue).
Bipartite graph with edges connecting table segments to passages
Query-relevant Node Expansion
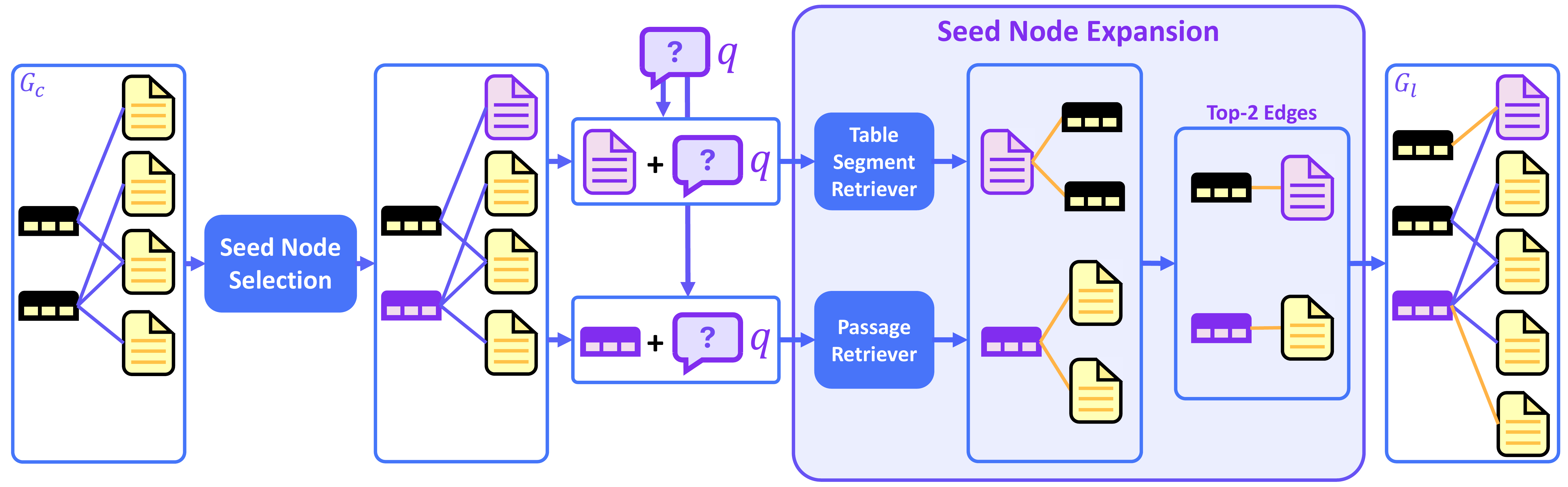
Figure 3: The beam search procedure for query-relevant node expansion with beam width b=2.
This stage enhances the retrieved subgraph by dynamically finding additional query-relevant nodes:
- Seed Node Selection: Identify top-b nodes most relevant to the query using all-to-all interaction reranking
- Expanded Query Retrieval: Combine seed nodes with query to retrieve related nodes from the complete bipartite graph
- Beam Search Optimization: Efficiently explore the search space with controlled beam width
Star-based LLM Refinement
Figure 4: Star-based LLM refinement with column-wise aggregation and passage verification.
This stage leverages LLM reasoning for advanced inference beyond semantic similarity:
Column-wise Aggregation
Restores original tables and performs aggregation operations (e.g., finding "most recent" or "highest") using LLM reasoning
Passage Verification
Decomposes the graph into star graphs and uses LLM to verify passage relevance, reducing hallucination risks
Experimental Results
Retrieval Accuracy on OTT-QA Development Set
| Model | AR@2 | AR@5 | AR@10 | AR@20 | AR@50 | nDCG@50 |
|---|---|---|---|---|---|---|
| OTTeR | 31.4 | 49.7 | 62.0 | 71.8 | 82.0 | 25.9 |
| DoTTeR | 31.5 | 51.0 | 61.5 | 71.9 | 80.8 | 26.7 |
| CORE | 35.3 | 50.7 | 63.1 | 74.5 | 83.1 | 25.4 |
| COS | 44.4 | 61.6 | 70.8 | 79.5 | 87.8 | 33.6 |
| COS w/ ColBERT & bge | 49.6 | 68.2 | 78.7 | 85.0 | 91.7 | 36.5 |
| HELIOS (Ours) | 63.3 | 76.7 | 85.0 | 90.4 | 94.2 | 47.0 |
HELIOS consistently outperforms all competitors across all metrics, achieving up to 42.6% improvement in AR@2 over the previous state-of-the-art COS model.
End-to-End QA Accuracy on OTT-QA
| Model | Dev Set | Test Set | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| OTTeR | 37.1 | 42.8 | 37.3 | 43.1 |
| DoTTeR | 37.8 | 43.9 | 35.9 | 42.0 |
| CORE | 49.0 | 55.7 | 47.3 | 54.1 |
| COS | 56.9 | 63.2 | 54.9 | 61.5 |
| HELIOS (Ours) | 59.3 | 65.8 | 57.0 | 64.3 |
HELIOS achieves 4.2% and 4.1% improvements in EM and F1 on the dev set, and 3.8% and 4.6% on the test set compared to COS, using a Fusion-in-Encoder (FiE) reader with 50 edges.
Performance Across Different Readers
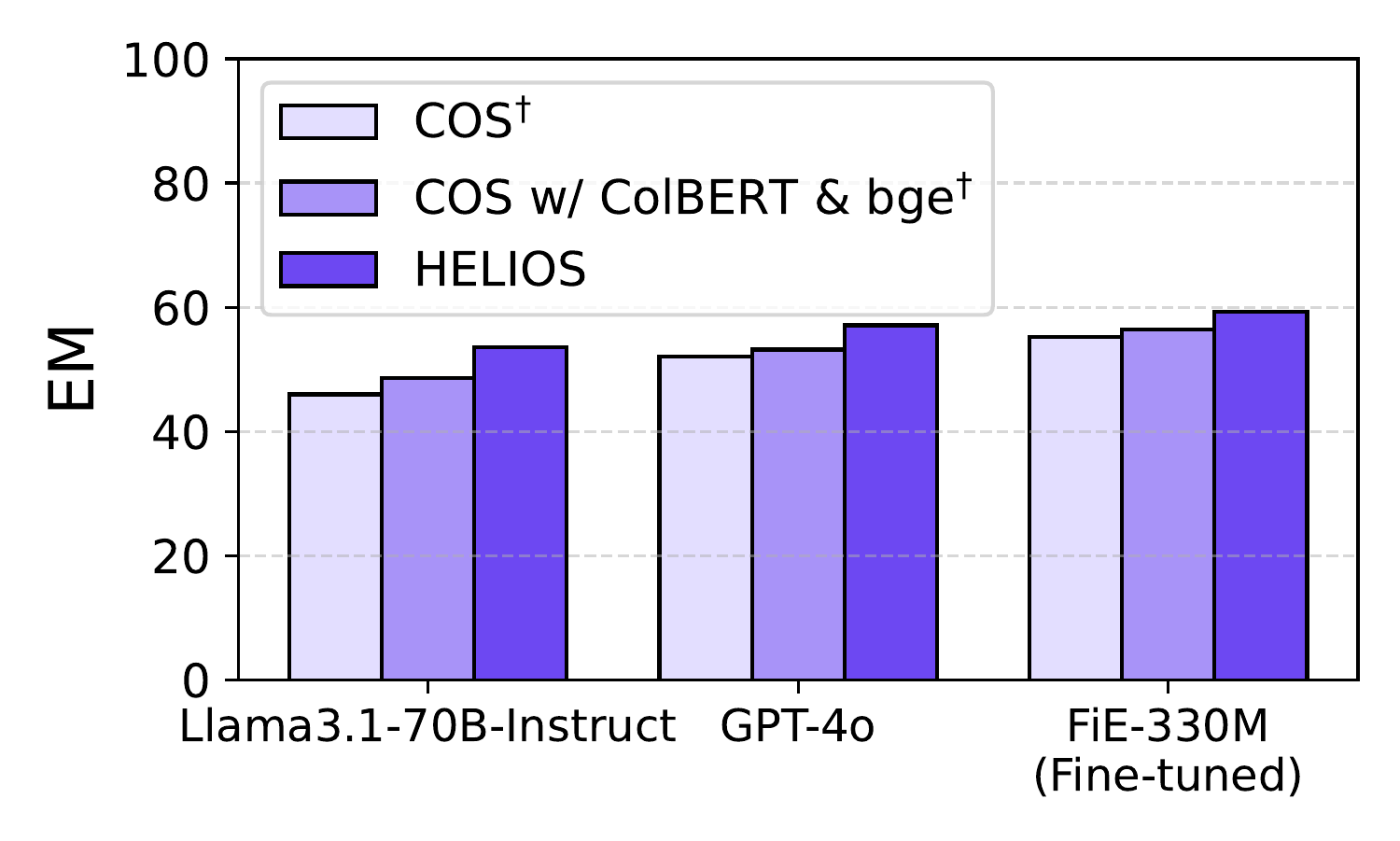
Exact Match (EM) Score
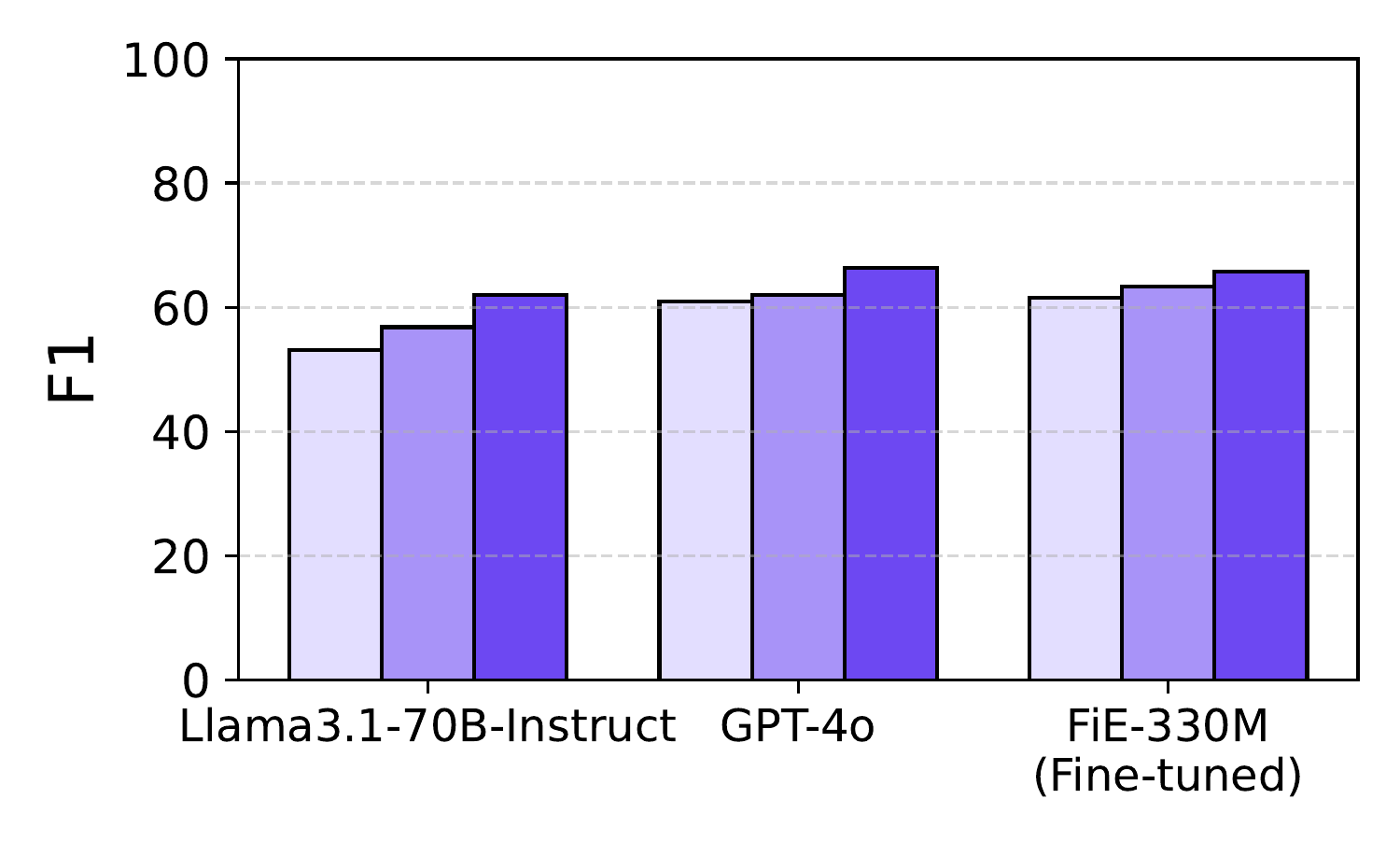
F1 Score
HELIOS improves performance across all readers, with an average EM improvement of 7.5% and F1 improvement of 6.6% compared to enhanced COS.
Ablation Study
QNE is crucial for generating query-relevant edges missed by offline entity linking.
SLR helps accurately identify query-relevant nodes in complex queries requiring logical inference, especially at low k values.
Impact of Retrieval Granularity
Node-level
Individual nodes lack context
Star Graph
Includes irrelevant passages
Edge-level (Ours)
Optimal balance of context
Qualitative Analysis

Figure 5: Qualitative analysis of Star-based LLM Refinement results, demonstrating how the LLM performs passage verification and column-wise aggregation to identify query-relevant information.
BibTeX
@inproceedings{park-etal-2025-helios,
title = "{HELIOS}: Harmonizing Early Fusion, Late Fusion, and {LLM} Reasoning for Multi-Granular Table-Text Retrieval",
author = "Park, Sungho and
Yun, Joohyung and
Lee, Jongwuk and
Han, Wook-Shin",
editor = "Che, Wanxiang and
Nabende, Joyce and
Shutova, Ekaterina and
Pilehvar, Mohammad Taher",
booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.acl-long.1559/",
doi = "10.18653/v1/2025.acl-long.1559",
pages = "32424--32444",
ISBN = "979-8-89176-251-0",
abstract = "Table-text retrieval aims to retrieve relevant tables and text to support open-domain question answering. Existing studies use either early or late fusion, but face limitations. Early fusion pre-aligns a table row with its associated passages, forming ``stars,'' which often include irrelevant contexts and miss query-dependent relationships. Late fusion retrieves individual nodes, dynamically aligning them, but it risks missing relevant contexts. Both approaches also struggle with advanced reasoning tasks, such as column-wise aggregation and multi-hop reasoning. To address these issues, we propose HELIOS, which combines the strengths of both approaches. First, the edge-based bipartite subgraph retrieval identifies finer-grained edges between table segments and passages, effectively avoiding the inclusion of irrelevant contexts. Then, the query-relevant node expansion identifies the most promising nodes, dynamically retrieving relevant edges to grow the bipartite subgraph, minimizing the risk of missing important contexts. Lastly, the star-based LLM refinement performs logical inference at the star graph level rather than the bipartite subgraph, supporting advanced reasoning tasks. Experimental results show that HELIOS outperforms state-of-the-art models with a significant improvement up to 42.6{\%} and 39.9{\%} in recall and nDCG, respectively, on the OTT-QA benchmark."
}